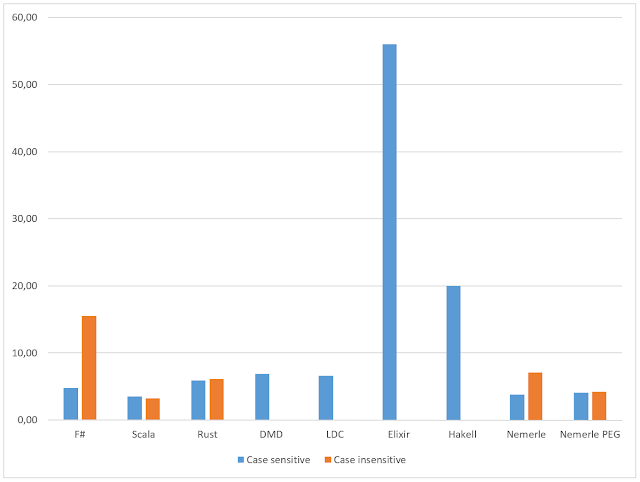
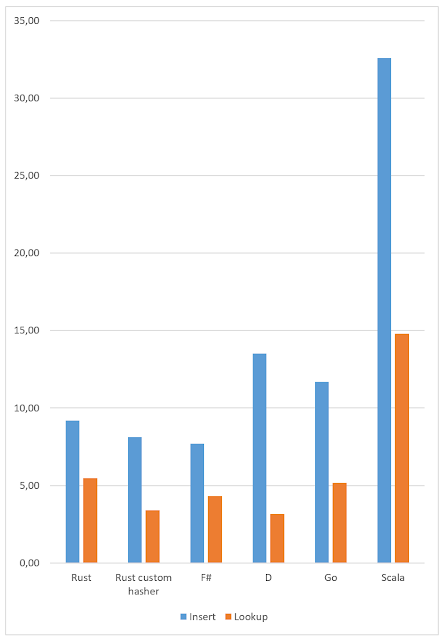
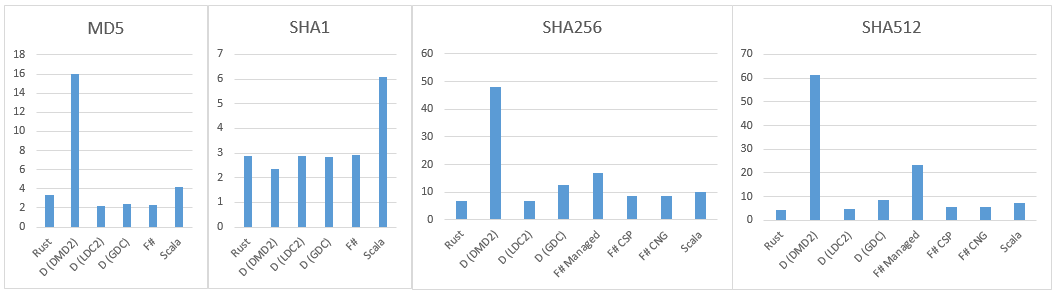
Let's compare performance of hashmap implementation in Rust, .NET, D (LDC) and Go. Rust: F#: As you can see, Rust is slower at about 17% on insersions and at about 21% on lookups. Update As @GolDDranks suggested on Twitter , since Rust 1.7 it's possible to use custom hashers in HashMap. Let's try it: Yes, it's significantly faster: additions is only 5% slower than .NET implementation, and lookups are 32% *faster*! Great. Update: D added LDC x64 on windows It's very slow at insertions and quite fast on lookups. Update: Go added Update: Scala added Compared to Scala all the other languages looks equally fast :) What's worse, Scala loaded all four CPU cores at almost 100% during the test, while others used roughly single core. My guess is that JVM allocated so many objects (each Int is an object, BTW), that 3/4 of CPU time was spend for garbage collecting. However, I'm a Scala/JVM noob, so I just could write the whole b...
Comments