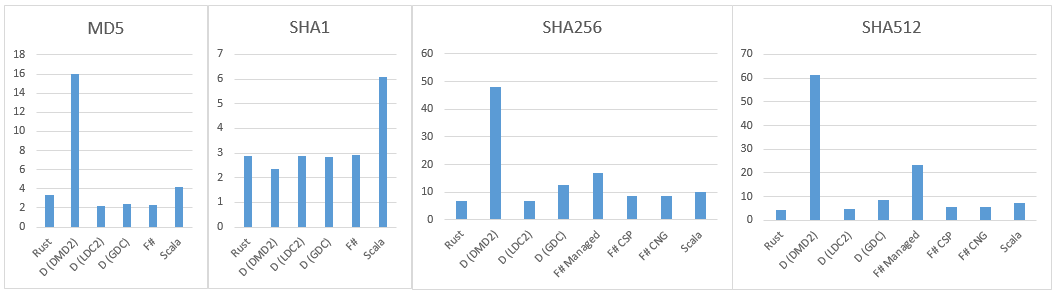
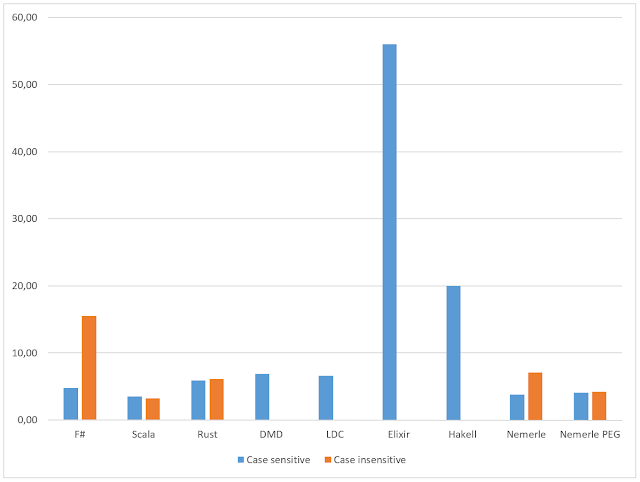
Regular expressions: Rust vs F# vs Scala
Let's implement the following task: read first 10M lines from a text file of the following format: then find all lines containing Microsoft namespace in them, and format the type names the usual way, like "Microsoft.Win32.IAssemblyEnum". First, F#: Now Rust: After several launches the file was cached by the OS and both implementations became non IO-bound. F# one took 29 seconds and 31MB of RAM at peak; Rust - 11 seconds and 18MB. The Rust code is as twice as long as F# one, but it's handling all possible errors explicitly - no surprises at runtime at all. The F# code may throw some exceptions (who knows what kind of them? Nobody). It's possible to wrap all calls to .NET framework with `Choice.attempt (fun _ -> ...)`, then define custom Error types for regex related code, for IO one and a top-level one, and the code'd be even longer then Rust's, hard to read and it would still give no guarantee that we catch all possible exceptions. Up...