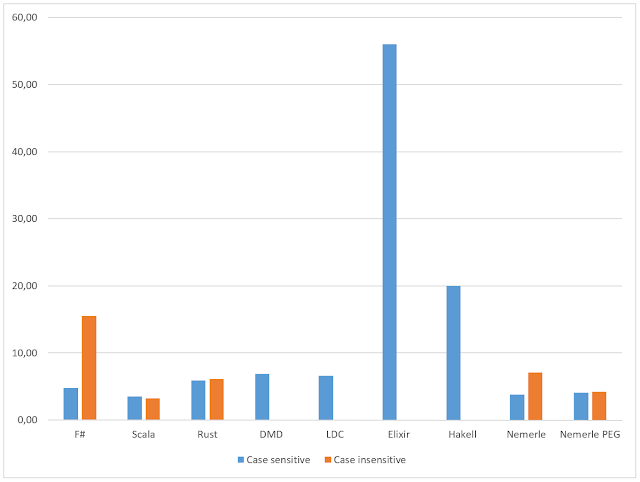
Let's implement the following task: read first 10M lines from a text file of the following format: then find all lines containing Microsoft namespace in them, and format the type names the usual way, like "Microsoft.Win32.IAssemblyEnum". First, F#: Now Rust: After several launches the file was cached by the OS and both implementations became non IO-bound. F# one took 29 seconds and 31MB of RAM at peak; Rust - 11 seconds and 18MB. The Rust code is as twice as long as F# one, but it's handling all possible errors explicitly - no surprises at runtime at all. The F# code may throw some exceptions (who knows what kind of them? Nobody). It's possible to wrap all calls to .NET framework with `Choice.attempt (fun _ -> ...)`, then define custom Error types for regex related code, for IO one and a top-level one, and the code'd be even longer then Rust's, hard to read and it would still give no guarantee that we catch all possible exceptions. Up...
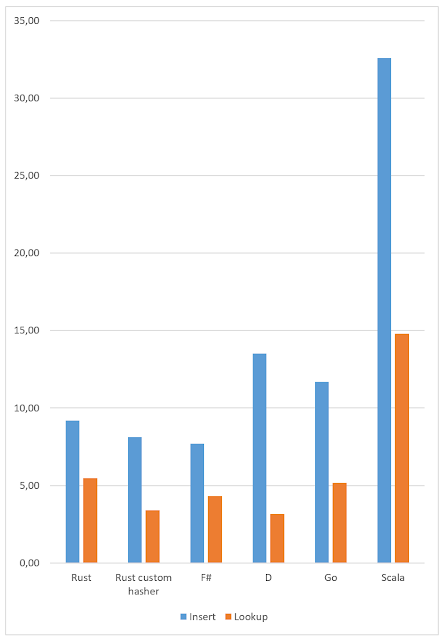
Let's compare performance of hashmap implementation in Rust, .NET, D (LDC) and Go. Rust: F#: As you can see, Rust is slower at about 17% on insersions and at about 21% on lookups. Update As @GolDDranks suggested on Twitter , since Rust 1.7 it's possible to use custom hashers in HashMap. Let's try it: Yes, it's significantly faster: additions is only 5% slower than .NET implementation, and lookups are 32% *faster*! Great. Update: D added LDC x64 on windows It's very slow at insertions and quite fast on lookups. Update: Go added Update: Scala added Compared to Scala all the other languages looks equally fast :) What's worse, Scala loaded all four CPU cores at almost 100% during the test, while others used roughly single core. My guess is that JVM allocated so many objects (each Int is an object, BTW), that 3/4 of CPU time was spend for garbage collecting. However, I'm a Scala/JVM noob, so I just could write the whole b...
 The Checkpoints + Raw File Staging in SSIS 2008 is an absolutely wonderful thing!
The Checkpoints + Raw File Staging in SSIS 2008 is an absolutely wonderful thing!
Comments