Regular expressions: Rust vs F# vs Scala
Let's implement the following task: read first 10M lines from a text file of the following format:
then find all lines containing Microsoft namespace in them, and format the type names the usual way, like "Microsoft.Win32.IAssemblyEnum".First, F#:
The Rust code is as twice as long as F# one, but it's handling all possible errors explicitly - no surprises at runtime at all. The F# code may throw some exceptions (who knows what kind of them? Nobody). It's possible to wrap all calls to .NET framework with `Choice.attempt (fun _ -> ...)`, then define custom Error types for regex related code, for IO one and a top-level one, and the code'd be even longer then Rust's, hard to read and it would still give no guarantee that we catch all possible exceptions.
Update 4 Jan 2016: Scala added:
Ok, it turns out that regex performance may depend on whether it's case sensitive or not. What's worse, I tested F# with case insensitive pattern, but Rust - for case sensitive. Anyway, as I've upgraded my machine recently (i5-750 => i7-4790K), I've rerun F# and Rust versions in both the regex modes and added Scala to the mix. First, case sensitive mode:
- F# (F# 4.0, .NET 4.6.1) - 4.8 secs
- Scala (2.11.7, Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_65) - 3.5 secs
- Rust (1.7.0-nightly (bfb4212ee 2016-01-01) - 5.9 secs
Now, case insensitive:
Although case sensitive patterns performs roughly the same on all the platforms, it's quite surprising that Rust is not the winner.
Scala is faster in case insensitive mode (?), Rust is slightly slower and now the question: what's wrong with .NET implementation?.. It performs more than 3 times slower that case sensitive and the others.
Update 4 Jan 2016: D added.
- F# (F# 4.0, .NET 4.6.1) - 15.5 secs
- Scala (2.11.7, Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_65) - 3.2 secs
- Rust (1.7.0-nightly (bfb4212ee 2016-01-01) - 6.1 secs
Although case sensitive patterns performs roughly the same on all the platforms, it's quite surprising that Rust is not the winner.
Scala is faster in case insensitive mode (?), Rust is slightly slower and now the question: what's wrong with .NET implementation?.. It performs more than 3 times slower that case sensitive and the others.
Update 4 Jan 2016: D added.
- regex - 10.6 s (DMD), 7.8 s (LDC)
- ctRegex! - 6.9 s (DMD), 6.6 s (LDC)
Update 6 Jan 2016: Elixir added:
Update 6 Jan 2016: Haskell added:
I takes 20 seconds.
Update 7 Jan 2016: Nemerle added:
It takes 3.8 seconds (case sensitive) and 7.1 seconds (case insensitive).
Update 8 Jan 2016: Nemerle PEG added:
It takes 4.1 seconds.
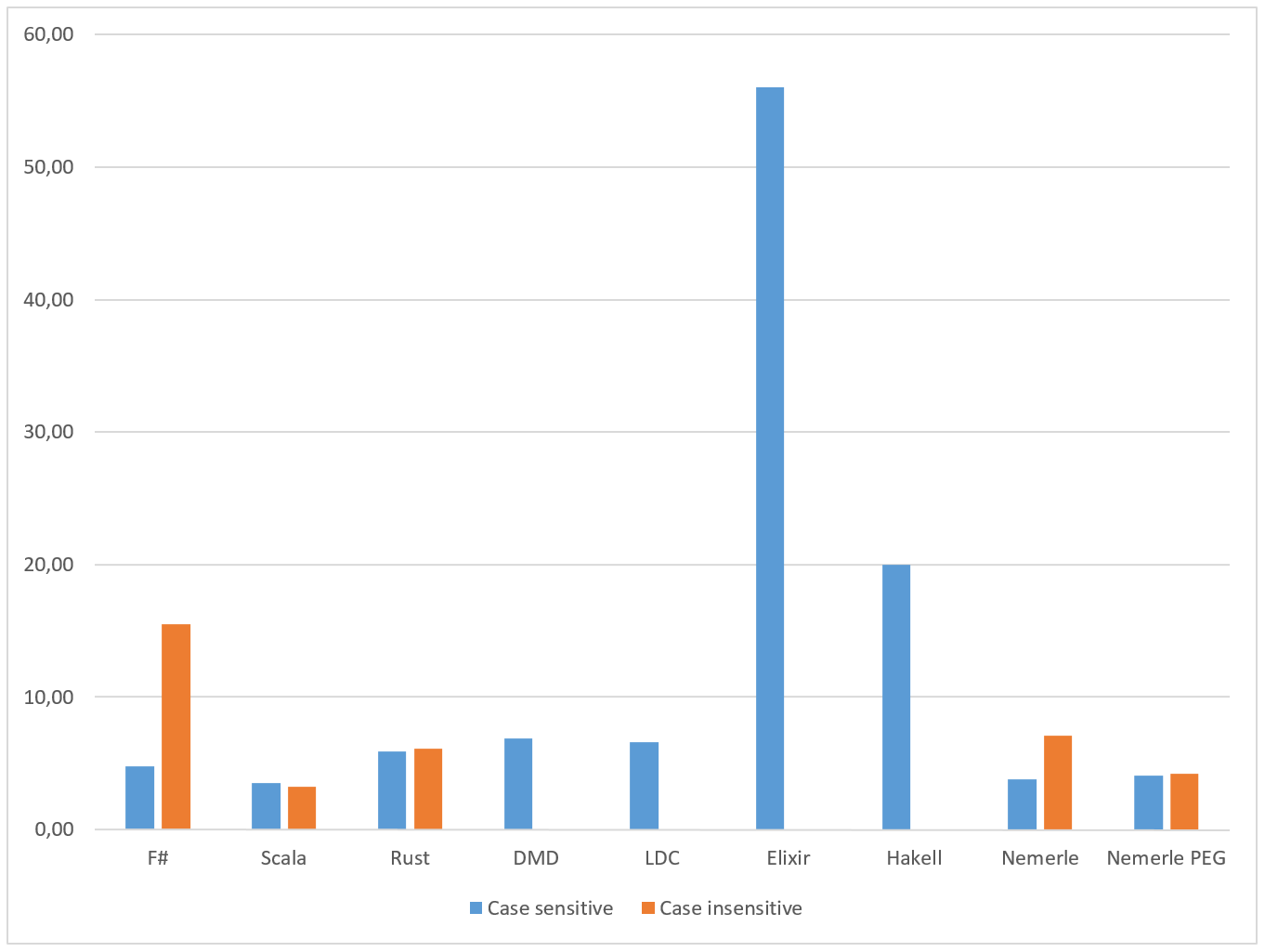
All results so far:
| Case sensitive | Case insensitive | |
| F# | 4,80 | 15,50 |
| Scala | 3,50 | 3,20 |
| Rust | 5,90 | 6,10 |
| DMD | 6,90 | |
| LDC | 6,60 | |
| Elixir | 56,00 | |
| Hakell | 20,00 | |
| Nemerle | 3,80 | 7,10 |
| Nemerle PEG | 4,10 | 4,20 |
Update 3 Dec 2017: Rust's regex crate updated and code cleanup, F# run on .NET Core 2.0:
F#
Rust
Rust version now performs 2x faster, F# is slower on case sensitive and faster on case insensitive on Core:
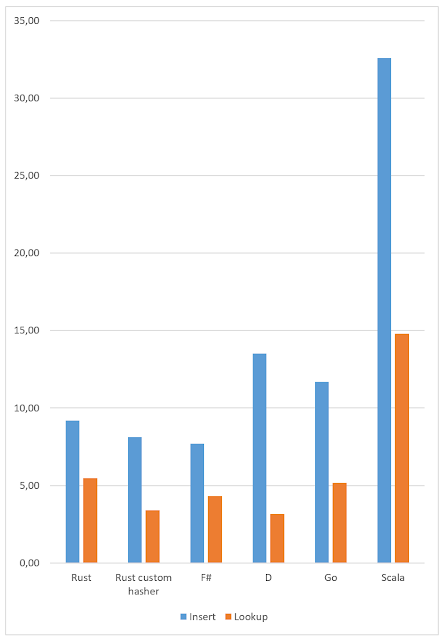
All results so far:
| Case sensitive | Case insensitive | |
| F# | 6,57 | 9,56 |
| Scala | 3,50 | 3,20 |
| Rust | 2,97 | 3,02 |
| DMD | 6,90 | |
| LDC | 6,60 | |
| Elixir | 56,00 | |
| Hakell | 20,00 | |
| Nemerle | 3,80 | 7,10 |
| Nemerle PEG | 4,10 | 4,20 |
I removed Elixir from the chart as it's a clear outsider and its results make the chart read harder:

Comments
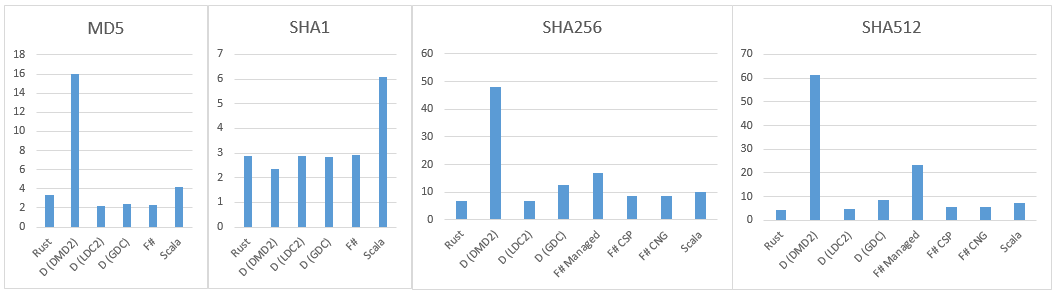
D(LDC): 5.778s
D(GDC): 5.612s
D(DMD): 5.267s
scalac: 5.748s
rustc: 9.287s
https://paste.ee/p/Bb1Ns
you may need to alter the filename on line 10, you appear to be on Windows and I adjusted it for my Linux OS.
It runs twice as fast as the original ctRegex implementation in your blog post for me. The output is the same, feel free to verify.
Elapsed: 3187
~/regex 3.17s user 0.04s system 99% cpu 3.217 total
Elapsed: 6283
~/regex2 6.15s user 0.14s system 99% cpu 6.307 total
compiled with ldc -O3 -release -boundscheck=off -singleobj regex.d
dmd version is ~70% slower now
Bye.
and unpacking Text. This now runs in about 5 seconds on my laptop. https://gist.github.com/raichoo/3ae8dd14699b1f731916
* the latest Rust compiler and regex crate
* F# 4.1 on .NET Core 2.0
Rust is not the leader, F# results is somewhat better.
.Net Online Course
Dot Net Training in Chennai | Dot Net Training in anna nagar | Dot Net Training in omr | Dot Net Training in porur | Dot Net Training in tambaram | Dot Net Training in velachery